Lorsqu’on compare des données quantitatives ou qualitatives en fonction des modalités d’une variable qualitative, on peut avoir des données qui sont non appariées (étude de type between-subject design en anglais) ou appariées (étude de type within-subject design en anglais). Avoir des données non appariées signifie que les données n’appartiennent pas aux mêmes individus. Un exemple simple, pour ce premier cas, peut être la comparaison de la taille entre les hommes et les femmes. Dans ce cas, les données quantitatives de taille selon les modalités de sexe proviendront forcément d’individus différents et ne formeront donc pas des paires. S’agissant des cas de données appariées, ils se retrouvent dans les études où plusieurs individus sont évalués plusieurs fois dans des conditions similaires ou différentes et que l’on cherche à comparer. En sciences du sport, un exemple relativement classique est de tester la performance d’endurance (variable quantitative) en ayant pris (condition de test) ou non (condition contrôle) une substance potentiellement ergogénique, la prise de substance ou non étant les modalités d’une même variable qualitative de type condition. Dans ce cas là, tous les individus auront des données dans les deux conditions et ces données seront donc appariées (dépendantes).
La notion d’appariement ou non peut bien sûr s’étendre aux cas de figure où il y aurait plus que deux groupes de valeurs à comparer. Toutefois, les procédures graphiques et calculatoires sont différentes selon que l’on a deux groupes ou plus. Ce chapitre s’intéresse seulement à la comparaison de deux groupes.
5.1 Comparaison sur une variable quantitative
5.1.1 Notions
5.1.1.1 Différences de moyennes standardisées
Les statistiques qui sont classiquement envisagées pour chiffrer les comparaisons entre deux groupes de valeurs numériques sont les différences de moyennes (associées respectivement aux deux groupes étudiés) standardisées, c’est-à-dire normalisées (ou, plus concrètement, divisées) par le degré d’hétérogénéité interindividuelle (une sorte d’écart-type) pour la variable étudiée (Lakens, 2013). Ces statistiques sont inhérentes aux tests \(t\) de Student et de Welch. Les différences de moyennes standardisées, qui de par leurs calculs sont sans unité, favorisent la possibilité de porter un jugement sur la grandeur relative de la différence de moyennes entre les groupes comparés et la possibilité de comparer cette différence avec celles observées dans d’autres études, en particulier celles traitant de thématiques différentes avec des variables et unités correspondantes différentes. Cela étant dit, il est important d’avoir en tête que la grandeur d’une différence de moyennes standardisée ne renseigne pas forcément directement sur l’importance pratique que la différence inter-groupe observée dans une étude pourrait avoir sur le terrain. Par exemple, une grande ou une petite différence standardisée pourraient correspondre à une même différence absolue entre deux moyennes (par exemple une distance en mètres) selon que le degré d’hétérogénéité interindividuelle dans l’étude est faible ou élevé, respectivement.
En principe, les différences de moyennes standardisées sont valides pour pouvoir faire des inférences dans une population seulement lorsque la variable étudiée suit une loi normale (soit pour chacun des deux groupes non appariés comparés, soit pour les différences intra-individu en cas de groupes appariés) et que les variances des deux groupes comparés (en cas de groupes non appariés) sont relativement identiques. Lorsqu’une de ces conditions n’est pas respectée, il est possible que l’estimation faite à partir de l’échantillon pour caractériser la population soit en général très imprécise. Aussi, dans ces cas là, mieux vaut utiliser une version dite “robuste” des différences de moyennes standardisées, tel qu’en procédant à une winsorisation des données avant de procéder aux calculs classiques (i.e., on remplace, dans les variables d’origine, les valeurs correspondant aux 20 % les plus faibles et celles correspondant aux 20 % les plus élevés par respectivement la valeur la plus basse avant les 20 % les plus faibles et la valeur la plus haute avant les 20 % les plus élevés) (Li, 2016). Une autre approche consiste à utiliser des statistiques qui ne font pas d’hypothèse sur la manière dont sont distribuées les données dans la population d’origine pour les groupes à comparer, telles que la corrélation bisériale des rangs qui est à associer aux tests statistiques de somme des rangs et des rangs signés de Wilcoxon. Enfin, une autre approche robuste qui peut être associée à divers tests de comparaison de deux groupes est la probabilité de supériorité. Ces deux dernières approches sont présentées plus en détails ci-après.
5.1.1.2 Dominance
La notion de dominance d’un groupe par rapport à un autre est à privilégier à la classique différence de moyennes standardisée lorsque les conditions d’analyse rendent cette statistique imprécise (i.e., absence de normalité en cas de groupes non appariés ou appariés, hétérogénéité des variances en cas de groupes non appariés). La corrélation bisériale des rangs (\(r_{rb}\)) est un moyen de caractériser la dominance d’un groupe par rapport à un autre. Cette statistique, située entre -1 et 1, est telle que des valeurs plus élevées indiquent que davantage de valeurs d’un groupe sont supérieures à celles de l’autre groupe. Une valeur de −1 signifie que toutes les observations dans le second groupe sont supérieures à celles du premier, tandis qu’une valeur de +1 signifie que toutes les observations dans le premier groupe sont supérieures à celles du second (source: site du package {effectsize}).
5.1.1.3 Langage commun
L’approche du langage commun consiste à caractériser une différence entre deux groupes en utilisant des termes relativement simples. Un exemple est de présenter la probabilité de supériorité, c’est-à-dire le % de chances (ou la probabilité) qu’un individu pris au hasard dans un groupe ait une valeur plus élevée qu’un individu pris au hasard dans le second groupe. D’autres statistiques peuvent aussi être calculées, notamment : le \(U_{1}\) de Cohen, qui désigne la proportion des deux distributions sans superposition des individus ; ou encore le \(U_{3}\) de Cohen, qui désigne la proportion d’un groupe qui a des valeurs plus faibles que la médiane de l’autre groupe (source: site du package {effectsize}).
5.1.2 Comparer deux groupes non appariés
5.1.2.1 Étudier graphiquement la comparaison
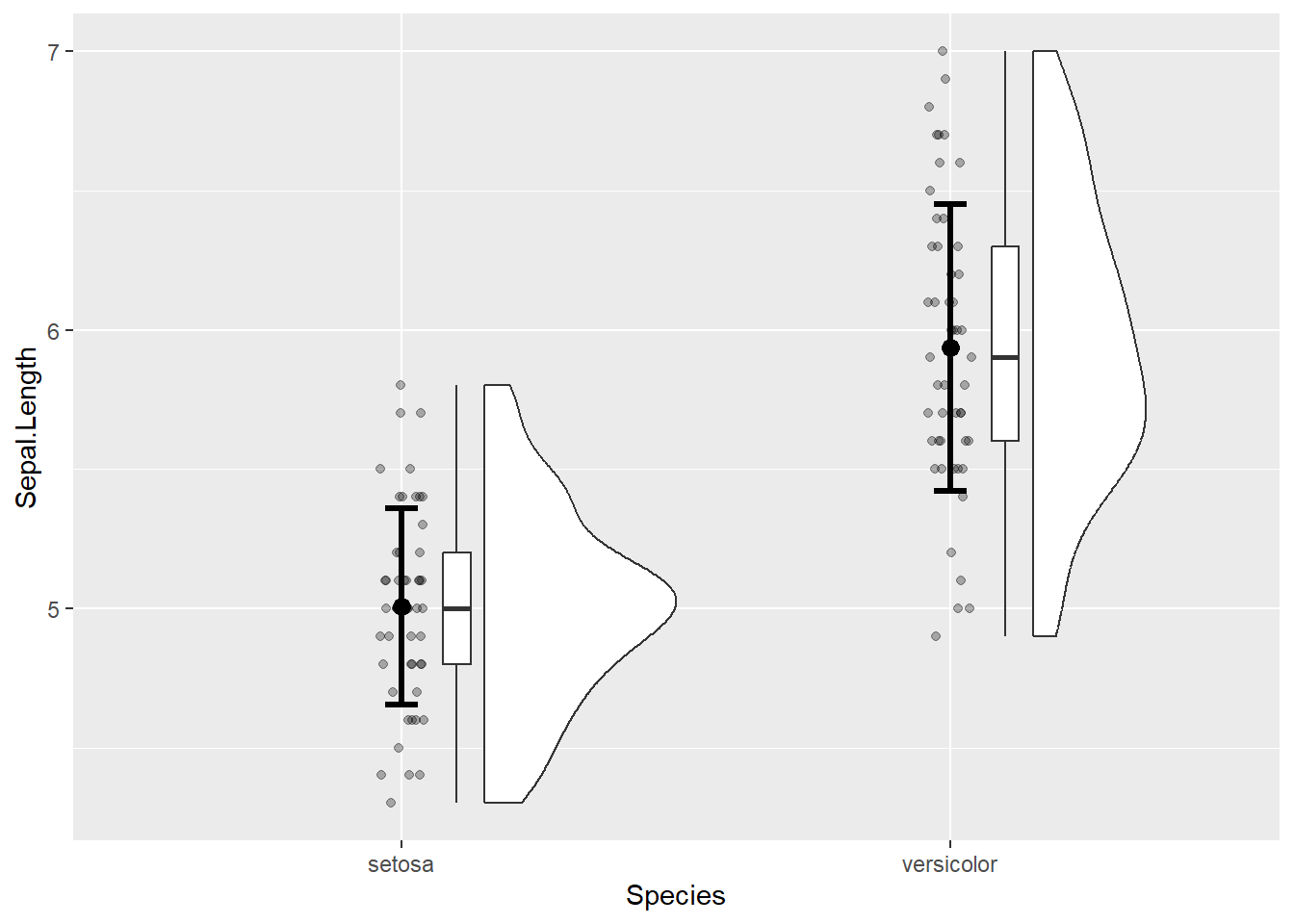
La Figure 5.1, qui est associée au bloc de code ci-dessous, montre un graphique approprié pour des données non appariées.
# Configuration du jeu de données pour l'exemple avec données non appariées.# Il s'agit ici d'obtenir le jeu de données `iris` avec seulement deux modalités # de la variable `Species`, cela en enlevant la modalité `virginica`.iris_two_species<-iris|>filter(Species!="virginica")|>mutate(Species =factor(Species, levels =c("setosa", "versicolor")))head(iris_two_species)
# Création du graphiqueggplot(data =iris_two_species, aes(x =Species, y =Sepal.Length))+geom_rain(point.args =rlang::list2(alpha =0.3))+stat_summary( geom ="errorbar", fun.data ="mean_sdl", fun.args =list(mult =1), linewidth =1.1, width =0.06)+stat_summary( geom ="point", fun ="mean", size =3)
Figure 5.1: Exemple de graphique pour une comparaison de deux groupes de valeurs non appariés (indépendants)
On note que pour montrer les moyennes et écarts-types sur la Figure 5.1, il a fallu utiliser la fonction stat_summary() du package Hmisc (qui est chargé automatiquement lors du chargement de ggplot2 après que Hmisc ait été installé). Cette fonction sert à visualiser un résumé statistique. Pour montrer les moyennes, on utilise fun = "mean", alors que pour montrer des écarts-types, on utilise fun.data = "mean_sdl". Pour les écarts-types, il faut ajouter fun.args = list(mult = 1) pour bien montrer une barre d’erreur ne correspondant qu’à un seul multiple de l’écart-type, car par défaut c’est deux fois l’écart-type qui est montré. On peut choisir la forme avec laquelle présenter le résumé statistique grâce à l’argument geom.
5.1.2.2 Étudier numériquement la comparaison
5.1.2.2.1 Différences de moyennes standardisées
5.1.2.2.1.1\(d_{s}\) et \(d_{av}\) de Cohen
Classiquement, l’indice statistique utilisé pour calculer une différence de moyennes de manière standardisée entre deux groupes indépendants, à partir d’échantillons de population, est le \(d_{s}\) de Cohen. Cette statistique se calcule en faisant la différence entre les moyennes des deux groupes à comparer, et en divisant cette différence par l’écart-type combiné (ou commun) des deux groupes. Ce calcul est montré ci-dessous :
avec \(\overline{X}_{1}\) et \(\overline{X}_{2}\) les moyennes des deux groupes comparés, \(N_{1}\) et \(N_{2 }\) les effectifs respectifs des deux groupes comparés, et \(\hat{\sigma}_{1}^2\) et \(\hat{\sigma}_{2}^2\) les variances respectives des deux groupes comparés. On peut remarquer qu’au dénominateur, la variance d’un groupe donné est multipliée par un coefficient calculé à partir de l’effectif du groupe, cela pour que le poids de la variance d’un groupe dans le calcul final soit ajusté par rapport à la taille du groupe. Dans R, si l’on voulait calculer \(d_s\) manuellement, cela donnerait ceci (à partir du jeu de données iris_two_species) :
# Calcul des paramètresX1<-iris_two_species|>filter(Species=="setosa")|>pull(Sepal.Length)|>mean()X2<-iris_two_species|>filter(Species=="versicolor")|>pull(Sepal.Length)|>mean()SD1<-iris_two_species|>filter(Species=="setosa")|>pull(Sepal.Length)|>sd()SD2<-iris_two_species|>filter(Species=="versicolor")|>pull(Sepal.Length)|>sd()N1<-iris_two_species|>filter(Species=="setosa")|>pull(Sepal.Length)|>length()N2<-iris_two_species|>filter(Species=="versicolor")|>pull(Sepal.Length)|>length()# Calcul de dsds<-(X1-X2)/sqrt(((N1-1)*SD1^2+(N2-1)*SD2^2)/(N1+N2-2))ds
[1] -2.104197
Heureusement, le \(d_{s}\) de Cohen peut être facilement calculé à l’aide de la fonction cohens_d() du package effectsize, qui nécessite d’être installé puis chargé avant d’être utilisé :
library(effectsize)ds<-cohens_d(Sepal.Length~Species, data =iris_two_species, paired =FALSE, pooled_sd =TRUE)ds
Cohen's d | 95% CI
--------------------------
-2.10 | [-2.59, -1.61]
- Estimated using pooled SD.
Dans cet exemple, on remarque qu’on a bien cherché à savoir comment les données de la variable Sepal.Length pouvaient différer en fonction (~) des modalités de la variable Species. Si la fonction nous donne un résultat, il faut toutefois bien faire attention au sens du calcul qui a été réalisé. Configurée de la sorte, la fonction cohens_d() réalise la différence modalité 1 - modalité 2. Il faut donc savoir quelle est la modalité 1 et quelle est la modalité 2 dans la variable Species pour ensuite pouvoir interpréter le signe du résultat, qui est négatif ici avec la valeur de -2.10. Pour ce faire, on peut utiliser la fonction levels() :
L’ordre des modalités affichées nous indique que setosa est la modalité 1, et que versicolor est la modalité 2. Par conséquent, le \(d_{s}\) de Cohen de -2.10 obtenu plus haut indique que la longueur des sépales (Sepal.Length) pour l’espèce setosa est inférieure à celles des sépales de l’espèce versicolor. Cette interprétation est en cohérence avec le graphique réalisé au préalable (cf. Figure 5.1). Si l’on avait voulu avoir le calcul inverse (versicolor - setosa), il aurait fallu reconfigurer l’ordre des modalités, par exemple à l’aide de la fonction fct_relevel() du package forcats comme montré à la fin du chapitre 3.
De manière importante, le calcul de \(d_s\) à partir d’un échantillon en vue d’avoir une estimation dans la population suppose que les variances des deux groupes dans la population d’intérêt soient similaires. Si cette supposition n’est pas valide ou est non désirée, alors il peut être préconisé de calculer un autre indicateur appelé \(d_{av}\) (voir explications ici), lequel consiste à diviser la différence de moyennes par un écart-type moyen :
En repartant des paramètres calculés précédemment, on peut manuellement obtenir cet indice comme ceci :
# Calcul de davdav<-(X1-X2)/sqrt((SD1^2+SD2^2)/2)dav
[1] -2.104197
On peut obtenir le \(d_{av}\) avec le package effectsize comme ceci (avec pooled_sd = FALSE) :
dav<-cohens_d(Sepal.Length~Species, data =iris_two_species, paired =FALSE, pooled_sd =FALSE)dav
Cohen's d | 95% CI
--------------------------
-2.10 | [-2.60, -1.60]
- Estimated using un-pooled SD.
On note que les valeurs de \(d_s\) et de \(d_{av}\) ne changent pas dans nos exemples car chaque modalité de la variable Species est associée au même nombre d’individus, ce qui revient à faire des calculs similaires pour les deux indices statistiques obtenus jusqu’à présent.
Malheureusement, il se trouve que \(d\) (\(d_s\) ou \(d_{av}\)) est indicateur qui est biaisé positivement lorsqu’il s’agit d’estimer la différence de moyennes standardisée à l’échelle de la population d’intérêt. Par « biaisé positivement », il faut comprendre que si une multitude d’études s’intéressait à calculer \(d\) et qu’on faisait la moyenne des résultats trouvés, alors on aurait une surestimation de la magnitude de la valeur de \(d\) dans la population (il s’agit d’un fait qui peut être démontré avec des simulations sur un ordinateur), cela notamment dans le cas où les études utiliseraient de petits échantillons (N < 20), selon Hedges et Okins (1985) cités par Lakens (2013).
5.1.2.2.1.2\(g_{s}\) et \(g_{av}\) de Hedges
Pour régler le problème de biais que pose le \(d\) de Cohen, un autre indicateur statistique a été proposé : le \(g\) de Hedges. Il s’agit en réalité du \(d\) de Cohen, mais qu’on modifie grâce à l’utilisation d’un facteur de correction. Une approximation de \(g\) est montrée ci-dessous (2013) :
\[g = d (1 - \frac{3}{4(N_{1} + N_{2}) - 9}),\]
avec \(d\) le \(d_s\) ou le \(d_{av}\) de Cohen, et \(N_{1}\) et \(N_{2}\) les effectifs respectifs des deux groupes comparés. En réalité, le calcul exact du facteur de correction est relativement complexe, et est montré avec l’équation ci-dessous (Kelley, 2005) :
\[g = d \frac{\Gamma(\frac{df}{2})}{\sqrt{\frac{df}{2}\Gamma(\frac{df-1}{2})}} \]
avec \(\Gamma\) la loi Gamma, et \(df\) ce qu’on appelle le nombre de degrés de liberté (qui est ici égal au nombre total d’individus moins 2). Dans les faits, les différences entre \(d\) et \(g\) sont relativement modestes, surtout avec \(N\) > 20 dans les groupes.
Dans R, le \(g_{s}\) de Hedges lié à un échantillon de population peut être calculé à l’aide de la fonction hedges_g() du package effectsize :
gs<-hedges_g(Sepal.Length~Species, data =iris_two_species, paired =FALSE, pooled_sd =TRUE)gs
Hedges' g | 95% CI
--------------------------
-2.09 | [-2.57, -1.60]
- Estimated using pooled SD.
Ici, la valeur ne change pas beaucoup par rapport à \(d_s\) car l’effectif n’est pas si petit que cela (\(N_{1}\) + \(N_{2}\) = 100 ici, ce qui fait que la correction appliquée au \(d_{s}\) de Cohen est minime).
Le \(g_{av}\) de Hedges lié à un échantillon de population peut aussi être calculé à l’aide de la fonction hedges_g() du package effectsize (avec pooled_sd = FALSE) :
gav<-hedges_g(Sepal.Length~Species, data =iris_two_species, paired =FALSE, pooled_sd =FALSE)gav
Hedges' g | 95% CI
--------------------------
-2.09 | [-2.58, -1.58]
- Estimated using un-pooled SD.
Par principe, il pourrait être recommandé de toujours utiliser le \(g\) (\(g_s\) ou \(g_{av}\)) de Hedges(Lakens, 2013).
5.1.2.2.1.3 Delta de Glass
Dans certains cas où l’on souhaiterait comparer les scores de deux groupes indépendants pour tester l’effet de deux conditions expérimentales différentes, l’expérimentation en tant que telle peut influencer, au-delà de la moyenne, l’écart-type de la variable réponse dans un des deux groupes. On peut se trouver dans ce genre de situation lorsque l’on compare les données post-programme d’un groupe entraîné ou traité à celles d’un groupe contrôle. En effet, le groupe entraîné/traité peut voir son écart-type changé au terme d’un programme en raison d’une réponse individuelle hétérogène à ce programme, ce qui ne sera pas en principe le cas du groupe contrôle. Dans ce genre de situations, des indices statistiques autres que le \(d\) de Cohen ou le \(g\) de Hedges mériteraient d’être calculés, tels que le delta (\(\Delta\)) de Glass (Lakens, 2013) :
Le calcul du \(\Delta\) de Glass est dans l’idée le même que celui du \(d\) de Cohen, sauf que la différence entre les moyennes des deux groupes n’est pas divisée par un écart-type lié aux deux groupes, mais par l’écart-type d’un seul des deux groupes, qui serait en principe celui qui représenterait la condition contrôle ou la condition de référence. Une pratique souvent recommandée pour comparer dans ce genre de situation les scores post-programme de deux groupes (un groupe entraîné/traité et un groupe contrôle) serait d’utiliser l’écart-type des scores du groupe contrôle obtenu en pré-programme (Lakens, 2013).
Dans R, le \(\Delta\) de Glass lié à un échantillon de population peut être calculé à l’aide de la fonction glass_delta() du package effectsize. Attention, l’écart-type utilisé dans le code suivant est celui de la variable quantitative associée à la modalité 2 de la variable qualitative, qui est toujours versicolor dans cet exemple (exemple dont le contexte n’est certes pas celui d’un programme dont on cherche l’effet, mais le principe d’utilisation du code reste le même).
gd<-glass_delta(Sepal.Length~Species, data =iris_two_species)gd
Notons quand même que l’utilisation du \(\Delta\) de Glass semble peu courante dans les études cherchant à tester l’effet d’un programme. L’une des difficultés liées à son utilisation est que cela suggère que les groupes à comparer soient identiques en pré-programme pour la variable étudiée. En général, des procédures un peu plus sophistiquées sont utilisées pour déterminer l’effet d’un programme, en particulier des procédures qui permettent de prendre en compte justement les différences qui peuvent exister entre les groupes en pré-programme.
5.1.2.2.1.4 Qualification de l’importance de la différence de moyennes standardisée
Une fois que l’on a calculé une taille d’effet, il est toujours intéressant d’essayer de formuler un jugement sur l’importance, l’ampleur de l’effet. En ce sens, des valeurs seuils ont été proposées dans la littérature pour les différences de moyennes standardisées (Cohen, 1988; in Lakens (2013)). Ces valeurs, valables pour interpréter des tailles d’effet dans le cadre d’une étude de type between-subject design, sont montrées dans le Tableau 5.1 ci-dessous.
Tableau 5.1: Proposition de termes pour qualifier l’importance d’une différence de moyennes standardisée
Cohen's d | 95% CI | Interpretation
-------------------------------------------
-2.10 | [-2.59, -1.61] | large
- Estimated using pooled SD.
- Interpretation rule: cohen1988
Hedges' g | 95% CI | Interpretation
-------------------------------------------
-2.09 | [-2.57, -1.60] | large
- Estimated using pooled SD.
- Interpretation rule: cohen1988
La corrélation bisériale des rangs fournit une mesure de la notion de dominance d’un groupe par rapport à l’autre. Sa formule pour la comparaison de deux groupes non appariés est la suivante :
avec \(rank(X_{i})\) et \(rank(Y_{i})\) les rangs des observations des variables \(X\) et \(Y\) toutes observations confondues, et \(N_{X}\) et \(N_{Y}\) les nombres d’observations pour les variables \(X\) et \(Y\) respectivement. Cette corrélation peut être obtenue manuellement dans R de la manière suivante :
# Calcul des rangs relatifs aux observations des deux modalités confonduesranks<-rank(iris_two_species$Sepal.Length)# Obtention du nombre d'observations pour setosa et versicolorn_setosa<-nrow(iris_two_species|>filter(Species=="setosa"))n_versicolor<-nrow(iris_two_species|>filter(Species=="versicolor"))# Calcul de la somme des rangs normalisée pour l'espèce `setosa`sum_rks_setosa<-(sum(ranks[which(iris_two_species$Species=="setosa")])-n_setosa*(n_setosa+1)/2)/(n_setosa*n_versicolor)# Calcul de la somme des rangs normalisée pour l'espèce `versicolor`sum_rks_versicolor<-(sum(ranks[which(iris_two_species$Species=="versicolor")])-n_versicolor*(n_versicolor+1)/2)/(n_setosa*n_versicolor)# Obtention de la corrélation bisérialejanitor::round_half_up(sum_rks_setosa-sum_rks_versicolor, 2)
[1] -0.87
La corrélation bisériale des rangs peut s’obtenir facilement avec la fonction rank_biserial() du package effectsize comme ceci :
rb<-rank_biserial(Sepal.Length~Species, data =iris_two_species, paired =FALSE)rb
r (rank biserial) | 95% CI
----------------------------------
-0.87 | [-0.91, -0.80]
Le résultat indique que les observations liées à la seconde modalité de la variable Species, qui est versicolor, ont en général des valeurs supérieures à celles relatives à la modalité setosa.
La grandeur de la corrélation bisériale des rangs peut être caractérisée à l’aide de la classification de Funder & Ozer (2019) proposée par défaut dans le package effectsize (Tableau 5.2) :
Tableau 5.2: Proposition de termes pour qualifier l’importance d’une corrélation bisériale des rangs
Très petite
Petite
Moyenne
Grande
Très grande
>=0.05
>=0.1
>=0.2
>=0.3
>=0.4
Pour obtenir une interprétation automatique en même temps que la valeur de corrélation, on peut utiliser la fonction interpret_rb() du package {effectsize} :
r (rank biserial) | 95% CI | Interpretation
---------------------------------------------------
-0.87 | [-0.91, -0.80] | very large
- Interpretation rule: funder2019
5.1.2.2.3 Langage commun
Pour comparer les groupes en utilisant la probabilité de supériorité, on peut utiliser la fonction p_superiority() du package effectsize comme ceci :
p_superiority(Sepal.Length~Species, data =iris_two_species, paired =FALSE, parametric =FALSE)
Le résultat indique que la probabilité d’avoir une valeur de Sepal.Length supérieure pour l’espèce setosa par rapport à l’espèce versicolor est de 7 % (réciproquement, la probabilité de supériorité pour l’espèce setosa est de 93 %). On note, dans le code ci-dessus, que l’argument parametric est configuré avec la valeur FALSE. Cela implique que l’estimation fournie est non paramétrique. De cette manière, la probabilité de supériorité est calculée à partir de la corrélation bisériale des rangs tel que : \(Pr(Superiority) = (r_{rb} + 1)/2\). Ce calcul serait le plus précis (le moins biaisé), notamment par rapport aux différences de moyennes standardisées classiques, sur un ensemble de scenarii de violation des conditions de normalité et d’hétérogénéité de variance (Li, 2016). Dans le cas où on utiliserait parametric = TRUE, alors la probabilité de supériorité serait calculée comme suit : \(Pr(superiority) = \phi(d/ \sqrt{2})\), avec \(d\) pour le \(d_{s}\) de Cohen.
5.1.3 Comparer deux groupes appariés
5.1.3.1 Étudier graphiquement la comparaison
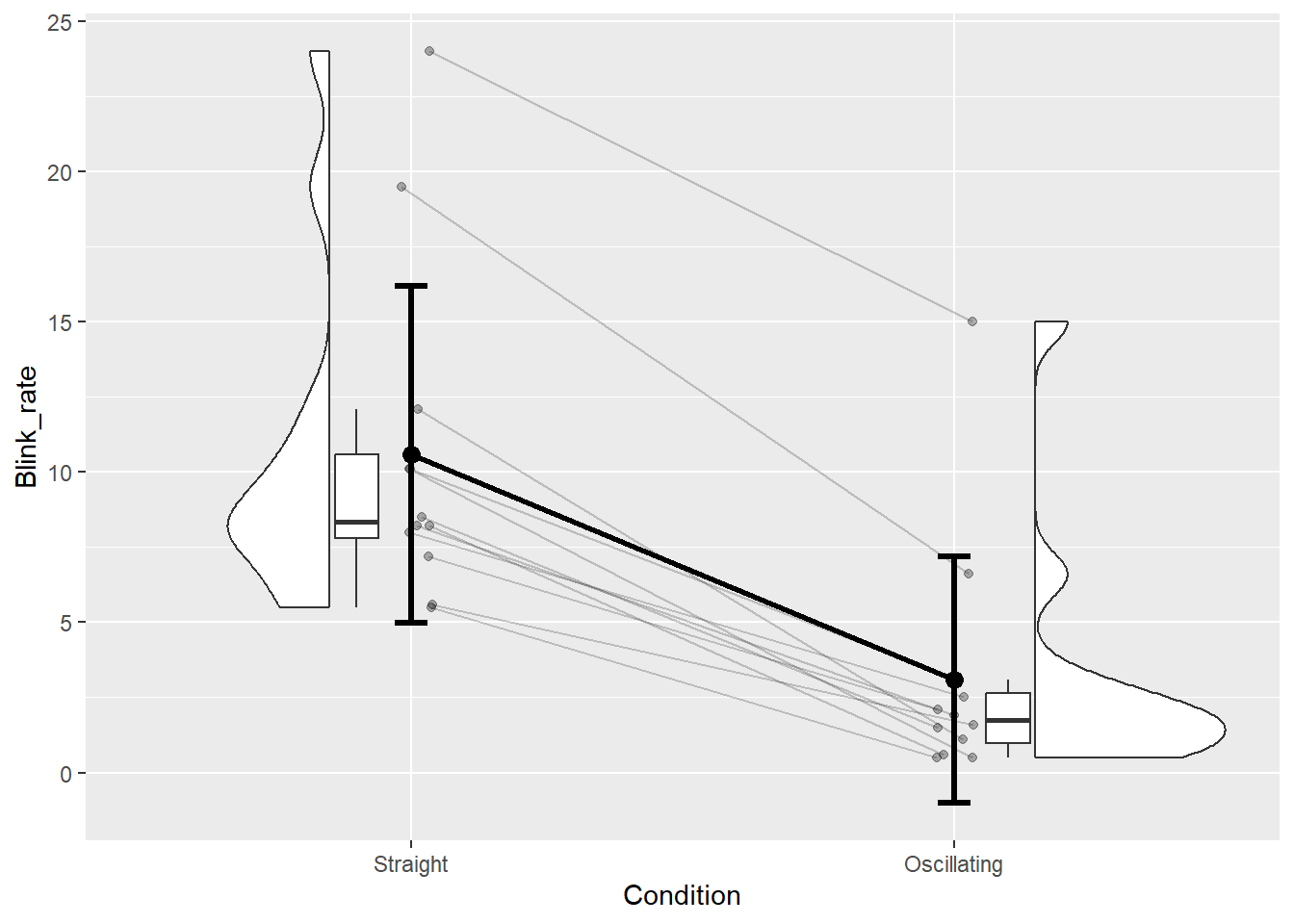
La Figure 5.2 montre une proposition de graphique dans le cas de l’étude d’une comparaison de deux groupes de données appariés. Pour cela, nous avons installé le package {PairedData} et chargé le jeu de données associé, appelé Blink. Pour information, Blink contient des données de taux de clignotement des yeux obtenues chez 12 sujets et dans deux conditions différentes : une tâche où il fallait diriger un stylo selon une trajectoire rectiligne (modalité Straight), et une tâche où il fallait diriger un stylo selon une trajectoire présentant des oscillations (Oscillating). Ce jeu de données a été un peu transformé pour pouvoir passer à l’étape de la conception graphique, comme montré ci-dessous.
# Charger le packagelibrary(PairedData)# Charger le jeu de donnéesdata(Blink)# Configurer le jeu de données pour l'exemple avec données appariéesBlink2<-Blink|>pivot_longer( cols =c(Straight, Oscillating), names_to ="Condition", values_to ="Blink_rate")|>mutate( Condition =fct_relevel(Condition, "Straight", "Oscillating"))# Visualisation du jeu de donnéeshead(Blink2)
# Création du graphiqueggplot(data =Blink2, aes(x =Condition, y =Blink_rate))+geom_rain( rain.side ="f1x1", id.long.var ="Subject", point.args =rlang::list2(alpha =0.3))+stat_summary(aes(group =1), fun ="mean", geom ="line", linewidth =1)+stat_summary( geom ="errorbar", fun.data ="mean_sdl", fun.args =list(mult =1), size =1.1, width =0.06)+stat_summary( geom ="point", fun ="mean", size =3)
Figure 5.2: Exemple de graphique pour une comparaison de deux groupes de valeurs appariés (dépendants)
Le graphique montré ci-dessus pour des données appariées contient des éléments graphiques supplémentaires par rapport à celui proposé pour les données non appariées : des lignes reliant les données individuelles, et une ligne reliant les statistiques qui représentent les tendances centrales (ici les moyennes). Ces deux types d’éléments graphiques sont importants pour explicitement montrer qu’il y a un lien entre les deux conditions de mesure (il s’agit des mêmes individus et donc du même groupe), et cela permet de mettre en évidence à la fois les trajectoires individuelles et celle du groupe entre les deux conditions de mesure.
Pour obtenir ces éléments supplémentaires, il a fallu configurer l’argument id.long.var de la fonction geom_rain() pour indiquer le nom de la variable sur laquelle se baser pour garder l’appariement des données individuelles entre les deux conditions et ainsi permettre un bon tracé des lignes individuelles. La ligne reliant les moyennes a été ajoutée grâce à la fonctionstat_summary() avec la particularité d’indiquer 1 pour l’argument group de la fonction aes() associée à la fonction stat_summary(). Enfin, l’argument rain.side de la fonction geom_rain() a été configuré de telle sorte à avoir les données des deux groupes en vis-à-vis, mais un autre choix aurait pu être fait.
5.1.3.2 Étudier numériquement la comparaison
5.1.3.2.1 Différences de moyennes standardisées
5.1.3.2.1.1\(d_{z}\) et \(d_{av}\) de Cohen
Le calcul classique pour obtenir la taille d’effet désignant l’écart de moyennes entre deux groupes de données dépendants est celui du \(d_{z}\)(Lakens, 2013), qui est montré ci-dessous :
\(\overline{X}_{diff}\) désignant la moyenne des différences relatives à chaque pair de valeurs obtenues dans les deux conditions comparées, et \(\hat{\sigma}_{diff}\) désignant l’écart-type de ces différences.
Dans R, on peut calculer manuellement \(d_z\) comme ceci (avec le jeu de données Blink) :
# Calcul des paramètresdiff<-Blink$Straight-Blink$Oscillatingmean_diff<-mean(diff)sd_diff<-sd(diff)# Calcul de dzdz<-mean_diff/sd_diffdz
[1] 2.811462
Le \(d_{z}\) peut être obtenu automatiquement avec la fonction rm_d() du package effectsize. Pour illustrer cela, nous allons utiliser le jeu de données Blink2 crée plus haut pour l’exemple de graphique :
dz<-rm_d(Blink_rate~Condition|Subject, data =Blink2, method ="z", adjust =FALSE)dz
d (z) | 95% CI
--------------------
2.81 | [1.55, 4.07]
Parce que la valeur de \(d_z\) dépend de la corrélation entre les deux groupes de valeurs comparés, certains auteurs préfèrent rapporter un autre indice statistique qui n’a pas cette propriété et qui en ce sens pourrait être davantage comparable au \(d\) de Cohen obtenu dans les études avec groupes indépendants. Parmi les candidats possibles, il y a notamment le \(d_{av}\) de Cohen (Lakens, 2013), dont la formule est montrée ci-dessous :
Ce calcul reviendrait donc à diviser la moyenne des différences (qui est égale à la différence de moyennes) par l’écart-type moyen relatif aux deux groupes de données. Manuellement cela donnerait (avec Blink2) :
# Calcul des paramètresX1<-Blink2|>filter(Condition=="Straight")|>pull(Blink_rate)|>mean()X2<-Blink2|>filter(Condition=="Oscillating")|>pull(Blink_rate)|>mean()SD1<-Blink2|>filter(Condition=="Straight")|>pull(Blink_rate)|>sd()SD2<-Blink2|>filter(Condition=="Oscillating")|>pull(Blink_rate)|>sd()N1<-Blink2|>filter(Condition=="Straight")|>pull(Blink_rate)|>length()N2<-Blink2|>filter(Condition=="Oscillating")|>pull(Blink_rate)|>length()# Calcul de davdav<-(X1-X2)/sqrt((SD1^2+SD2^2)/2)dav
[1] 1.525146
Le \(d_{av}\) pour données appariées peut être obtenu automatiquement avec la fonction rm_d() du package effectsize.
dav<-rm_d(Blink_rate~Condition|Subject, data =Blink2, method ="av", adjust =FALSE)dav
d (av) | 95% CI
---------------------
1.53 | [1.22, 1.83]
5.1.3.2.1.2\(g_{z}\) et \(g_{av}\) de Hedges
Comme pour les \(d\) de Cohen calculés dans le cadre de groupes non appariés, les \(d\) de Cohen obtenus avec groupes appariés sont positivement biaisés. À nouveau, ces indices statistiques peuvent être corrigés avec le même facteur de correction montré pour le \(g\) de Hedges dans la partie sur les groupes non appariés Toutefois, \(g_{av}\) ne serait malgré tout pas complètement non biaisé (Lakens, 2013).
Pour obtenir \(g_z\) :
gz<-rm_d(Blink_rate~Condition|Subject, data =Blink2, method ="z", adjust =TRUE)gz
d (z) | 95% CI
--------------------
2.61 | [1.44, 3.79]
- Adjusted for small sample bias.
Pour obtenir \(g_{av}\) :
gav<-rm_d(Blink_rate~Condition|Subject, data =Blink2, method ="av", adjust =TRUE)gav
d (av) | 95% CI
---------------------
1.42 | [1.13, 1.70]
- Adjusted for small sample bias.
Pour obtenir une interprétation des valeurs, on peut reprendre les procédures décrites pour les cas de groupes non appariés.
5.1.3.2.2 Dominance
Comme dans le cas de données non appariées, la corrélation bisériale des rangs peut être utilisée pour fournir une mesure de la notion de dominance d’une condition par rapport à une autre. Sa formule pour la comparaison de deux groupes appariés est la suivante :
avec \(SignedRank(X_{i} - Y_{i}))\) les rangs signés associés aux observations des modalités \(X\) et \(Y\) toutes observations confondues, et \(N\) le nombre d’individus étudiés. Cette corrélation peut être obtenue manuellement dans R de la manière suivante :
# Exemple avec le jeu de données `Blink2` crée plus haut# On cherche à comparer les condition `Straight`et `Oscillating` pour la variable `Condition` head(Blink2)
# Calcul des différences entre les modalitésdiffs<-Blink2[Blink2$Condition=="Straight", "Blink_rate"]-Blink2[Blink2$Condition=="Oscillating", "Blink_rate"]# Calcul des rangs signés relatifs aux observations des deux modalités confonduesranks<-datawizard::ranktransform(diffs, sign =TRUE)|>pull(Blink_rate)# Obtention du nombre d'individusn<-nrow(Blink2|>filter(Condition=="Straight"))# Calcul de la somme des rangs positifs normaliséesum_rks_pos<-sum(ranks[ranks>0])/(n*(n+1)/2)# Calcul de la somme des rangs négatifs normaliséesum_rks_neg<--sum(ranks[ranks<0])/(n*(n+1)/2)# Obtention de la corrélation bisérialejanitor::round_half_up(sum_rks_pos-sum_rks_neg, 2)
[1] 1
La corrélation bisériale des rangs peut s’obtenir facilement avec la fonction rank_biserial() du package effectsize comme ceci :
rb<-rank_biserial(Blink2|>filter(Condition=="Straight")|>pull(Blink_rate),Blink2|>filter(Condition=="Oscillating")|>pull(Blink_rate), data =Blink2, paired =TRUE)rb
r (rank biserial) | 95% CI
--------------------------------
1.00 | [1.00, 1.00]
Le résultat indique que les observations liées à la deuxième modalité de la variable Condition, qui est Oscillating, ont systématiquement des valeurs inférieures à celles relatives à la modalité Straight (pour un même individu).
Pour obtenir une interprétation des valeurs, on peut reprendre les procédures décrites pour les cas de groupes non appariés.
5.1.3.2.3 Langage commun
Pour comparer les groupes en utilisant la probabilité de supériorité, on peut à nouveau utiliser la fonction p_superiority() du package effectsize comme ceci :
Le résultat indique que la probabilité d’avoir une valeur de Blink_rate supérieure pour la condition Oscillating par rapport à la condition Straight est de 100 % (réciproquement, la probabilité de supériorité pour la condition Straight est de 0 %).
5.2 Comparaison sur une variable qualitative
Pour cette partie, on s’appuie sur le jeu de données qui a permis par le passé l’étude comparative des taux de réussite des femmes et des hommes à l’Université de Berkeley en 1973 (Bickel et al., 1975). Un aperçu du jeu de données est montré ci-dessous :
# Créer variable Départementdepartment<-c(rep("A", 4),rep("B", 4),rep("C", 4),rep("D", 4),rep("E", 4),rep("F", 4))# Créer variable Résultatresult<-c(rep("Admitted", 2),rep("Rejected", 2),rep("Admitted", 2),rep("Rejected", 2),rep("Admitted", 2),rep("Rejected", 2),rep("Admitted", 2),rep("Rejected", 2),rep("Admitted", 2),rep("Rejected", 2),rep("Admitted", 2),rep("Rejected", 2))# Créer variable Sexesex<-c("Male","Female","Male","Female","Male","Female","Male","Female","Male","Female","Male","Female","Male","Female","Male","Female","Male","Female","Male","Female","Male","Female","Male","Female")# Effectifseffectif<-c(512,89,313,19,353,17,207,8,120,202,205,391,138,131,279,244,53,94,138,299,22,24,351,317)# Créer data frameres<-data.frame( department =department, result =result, sex =sex, effectif =effectif)|>lapply(rep, effectif)|>as.data.frame()|>mutate( id =seq_along(sex), sex =fct_recode(sex, "Femmes"="Female", "Hommes"="Male"), result =fct_recode(result, "Admis"="Admitted", "Refusé"="Rejected"))|>dplyr::select(id, sex, department, result)# Aperçu du jeu de donnéeshead(res)
id sex department result
1 1 Hommes A Admis
2 2 Hommes A Admis
3 3 Hommes A Admis
4 4 Hommes A Admis
5 5 Hommes A Admis
6 6 Hommes A Admis
5.2.1 Étudier graphiquement la comparaison
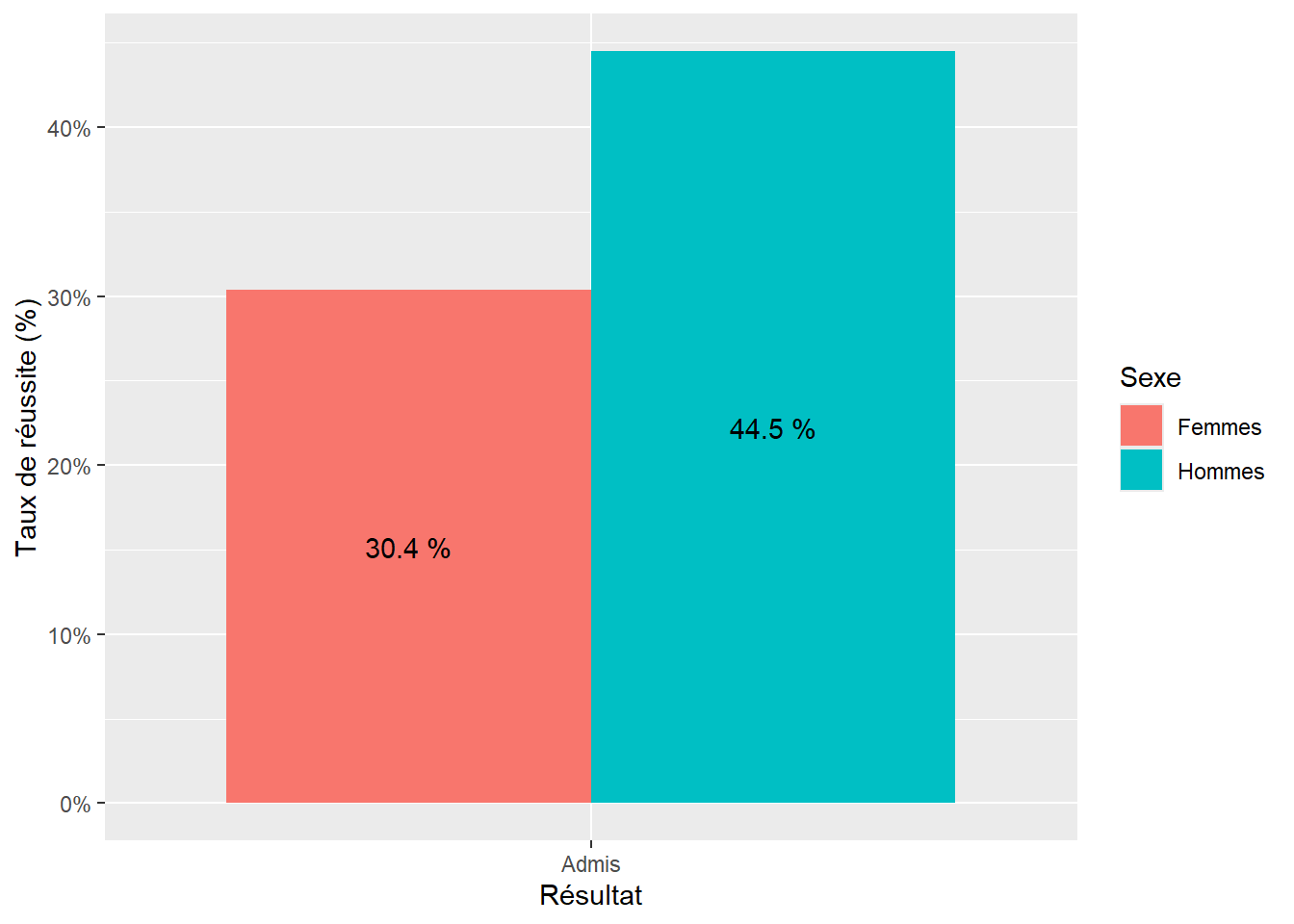
On s’intéresse donc à la comparaison du taux de réussite des femmes et des hommes sur l’ensemble de l’Université de Berkeley. Un graphique qui peut être fait pour cette étude est le suivant :
# Créer le jeu de donnéesres_by_sex<-res|>count(sex, result)|>group_by(sex)|>mutate(prop =janitor::round_half_up(n/sum(n)*100, 1))# Créer le graphiqueres_by_sex|>filter(result=="Admis")|>ggplot(aes(x =result, y =prop, fill =sex))+geom_bar(stat ="identity", position ="dodge")+geom_text(aes(y =prop/2, label =paste0(prop, " %")), position =position_dodge(.9))+scale_y_continuous(labels =scales::label_percent(scale =1))+labs(x ="Résultat", y ="Taux de réussite (%)", fill ="Sexe")
Figure 5.3: Taux de réussite des étudiants femmes et hommes à l’Université de Berkeley en 1973, approche globale (Bickel et al., 1975)
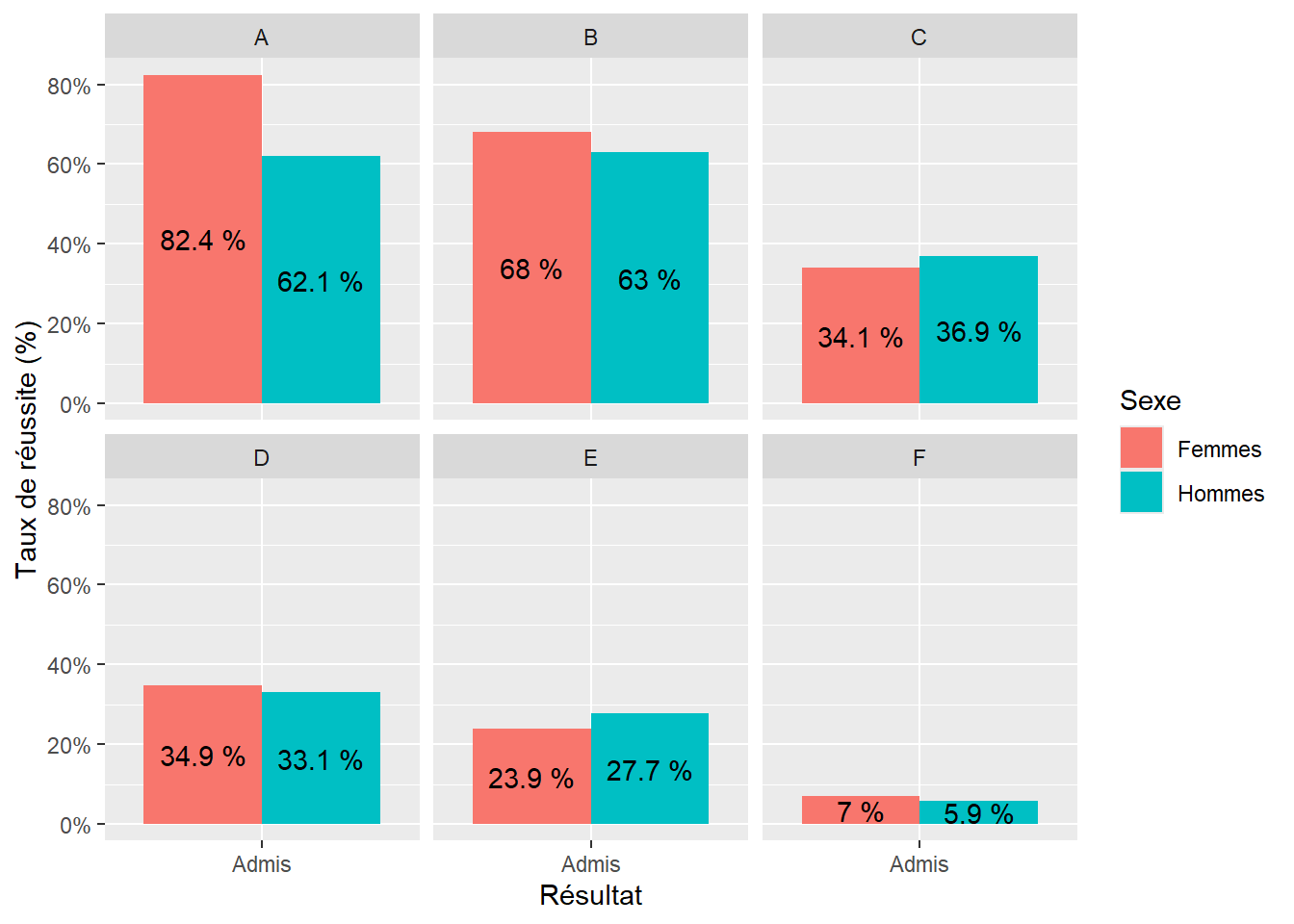
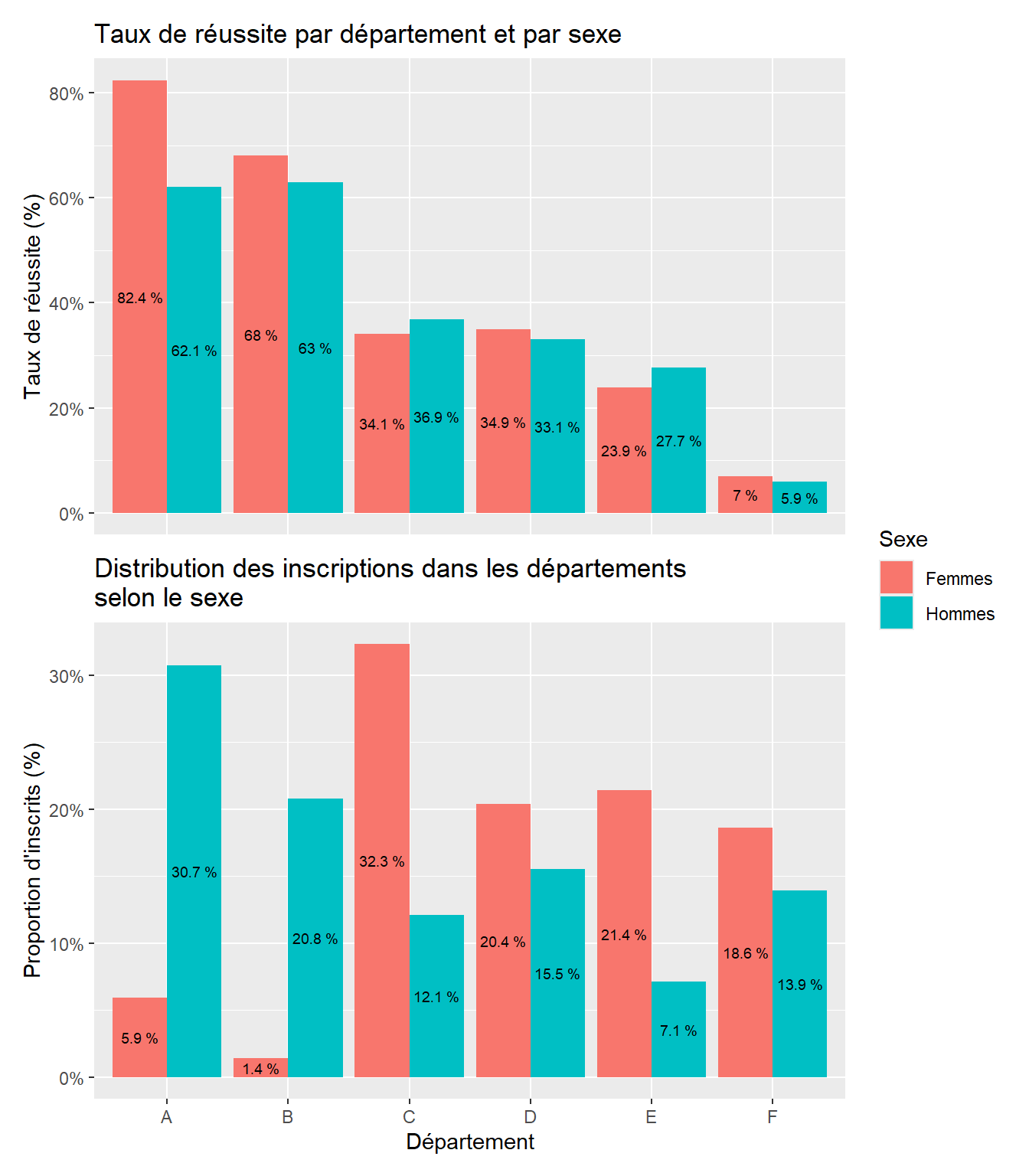
On voit ainsi qu’à l’échelle de l’Université, le taux de réussite des femmes était inférieur à celui des hommes. Toutefois, une analyse par département permettait de voir que les taux de réussite des femmes étaient en réalité supérieurs voire nettement supérieurs à ceux des hommes dans la plupart des départements (cf. Figure 5.4).
Figure 5.4: Taux de réussite des étudiants femmes et hommes à l’Université de Berkeley en 1973, approche par département (Bickel et al., 1975)
Cette situation, qui peut paraître étonnante, illustre ce qu’on appelle un paradoxe de Simpson. Dans le cas présent, l’apparent paradoxe s’explique par le fait que les femmes avaient en proportion davantage candidaté que les hommes dans des départements où le taux de réussite global était moins bon. Ceci est illustré sur la Figure 5.5.
Figure 5.5: Mise en avant du département d’inscription comme facteur confondant dans l’étude du lien entre le sexe et le taux de réussite à l’Université de Berkeley en 1973 (Bickel et al., 1975)
Autrement dit, les hommes avaient un taux de réussite global bien meilleur que celui des femmes parce que, comparativement aux femmes, les hommes s’étaient en proportion davantage engagés dans les départements où les taux de réussite étaient bien meilleurs.
5.2.2 Étudier numériquement la comparaison
5.2.2.1 Différence de risque
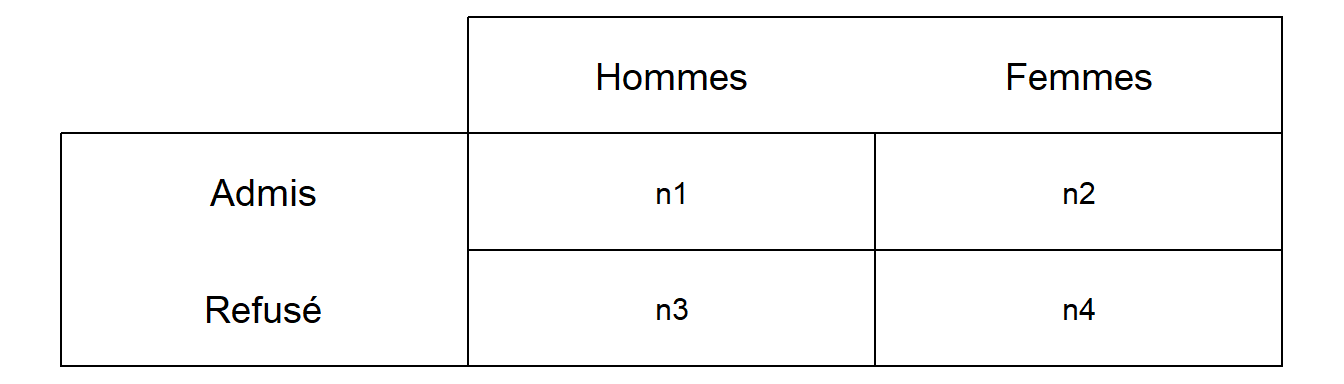
La différence de risque est une différence de proportions. La notion de risque peut ne pas être très pertinente pour certains contextes, comme le cas présenté ci-avant, mais elle l’est particulièrement dans un contexte de santé. Pour comprendre le calcul du risque puis de la différence de risque, regardons le tableau ci-dessous appliqué à l’exemple de notre étude sur la réussite à l’Université de Berkeley (Figure 5.6).
Figure 5.6: Tableau de contingence schématique pour comprendre le calcul des risques et des cotes
Dans le tableau ci-dessus, chaque case contenant un « n » est un effectif. Si l’on désire connaître le risque (ou plutôt la chance ici) d’être admis dans le groupe des femmes (\(p_{H/Adm}\)) et dans le groupe des hommes (\(p_{F/Adm}\)), on fait les calculs suivants :
\[p_{H/Adm} = \frac{n_{1}}{n_{1} + n_{3}}\]
\[p_{F/Adm} = \frac{n_{n2}}{n_{2} + n_{4}}\]
La différence de risque (ou plutôt de chance ici) d’être admis pour les femmes par rapport aux hommes, notée \(DR\), est alors :
\[DR = p_{H/Adm} - p_{F/Adm} \] Manuellement, dans R, on aurait donc :
# Réarangement des niveaux de sexeres$sex<-factor(res$sex, levels =c("Hommes", "Femmes"))# Création du tableau de contingencetab<-with(res, table(result, sex))tab
sex
result Hommes Femmes
Admis 1198 557
Refusé 1493 1278
# Obtention de p(H/Adm)p_H_Adm<-1198/(1198+1493)*100p_H_Adm
[1] 44.51877
# Obtention de p(F/Adm)p_F_Adm<-557/(557+1278)*100p_F_Adm
[1] 30.35422
# Calcul de la différence de risquejanitor::round_half_up(p_H_Adm-p_F_Adm, 2)
[1] 14.16
La différence de risque peut aussi être automatiquement obtenue avec la fonction arr() du package effectsize, comme ceci :
ARR | 95% CI
-------------------
0.14 | [0.11, 0.17]
Le résultat indique que les hommes avaient une différence absolue de taux de réussite de +14 % par rapport aux femmes.
5.2.2.2 Risque relatif
Le risque relatif, noté \(RR\), reprend les mêmes informations que celles utilisées pour la différence de risque (\(p_{H/Adm}\) et \(p_{F/Adm}\)). Ce qui change, c’est qu’il ne s’agit plus d’une différence, mais d’un rapport entre les risques présentés par les groupes comparés. Sa formule pour comparer le groupe des hommes au groupe des femmes dans notre exemple débuté plus haut est la suivante :
Risk ratio | 95% CI
-------------------------
1.47 | [1.35, 1.59]
Le résultat indique que le taux de réussite des hommes était 1.47 fois plus élevé que celui des femmes.
5.2.2.3 Rapports des cotes
Le rapport des cotes, noté \(OR\) pour Odds ratio en anglais, est une statistique dont le calcul peut à nouveau se comprendre à l’aide d’un tableau de contingence. Si l’on reprend le tableau de la Figure 5.6, on peut dire que la cote pour le fait d’être admis versus le fait d’être refusé dans le groupe des hommes est \(n_{1}\)/\(n_{3}\) et la cote pour le fait d’être admis versus le fait d’être refusée dans le groupe des femmes est \(n_{2}\)/\(n_{4}\). Le rapport des cotes pour les hommes versus celui pour les femmes dans ce cas-là peut se calculer comme ceci :
\[ OR = \frac{n_{1} / n{_{3}}}{n_{2} / n{_{4}}}\]
Le rapport des cotes est toujours ≥0. Une valeur en-dessous de 1 signifie « moins de chances/risques », une valeur de 1 signifie « chances/risques équivalent(e)s », et une valeur au-dessus de 1 signifie « plus de chances ou de risques ». Le chiffre obtenu renseigne toujours sur un niveau de chances pour le groupe au numérateur par rapport au niveau de chances concernant le groupe au dénominateur.
Odds ratio | 95% CI
-------------------------
1.84 | [1.62, 2.09]
Le résultat indique que la cote pour le fait d’être admis chez les garçons était 1.84 fois plus élevée que chez les filles.
5.3 Résumé
L’analyse graphique de la comparaison de deux groupes de valeurs numériques peut se faire à l’aide de raincloud plots.
L’analyse consistant à comparer deux groupes sur une variable quantitative peut consister à calculer une différence de moyennes standardisée. Les indices de différence de moyennes standardisée non biaisés sont les \(g_{s}\) et \(g_{av}\) de Hedges en cas de groupes non appariés et les \(g_{z}\) et \(g_{av}\) de Hedges en cas de groupes appariés et peuvent être calculés respectivement avec les fonctions effectsize::hedges_g() et effectsize::rm_d(). Afin d’éviter la supposition que les variances des groupes comparés sont égales (avec des groupes non appariés) ou pour rendre les résultats d’études avec groupes appariés plus comparables avec les études ayant utilisé des groupes non appariés, le \(g_{av}\) de Hedges pourrait être privilégié. Lorsque les conditions de normalité et/ou d’homogénéité des variances ne son pas présentes, mieux vaut utiliser des indicateurs statistiques plus robustes, tels que la corrélation bisériale des rangs qui traduit la notion de dominance d’un groupe sur un autre, et qui peut être obtenue avec la fonction effectsize::rank_biserial(). Un autre indicateur qu’il peut être intéressant de proposer quelles que soient les distributions des données est la probabilité de supériorité, qui s’inscrit dans l’utilisation d’un langage commun, et qui peut être obtenue avec la fonction effectsize::p_superiority().
L’analyse consistant à comparer deux groupes sur une variable qualitative peut s’effectuer graphiquement à l’aide de diagrammes en barres et numériquement via la différence de risque, le rapport de risque, et le rapport de cotes. Ces derniers indices statistiques peuvent être obtenus respectivement à l’aide des fonctions effectsize::arr(), effectsize::riskratio() et effectsize::oddsatio().
Bickel, P. J., Hammel, E. A., & O’Connell J, W. (1975). Sex Bias in Graduate Admissions: Data from Berkeley. Science, 187(4175), 398‑404. https://doi.org/10.1126/science.187.4175.398
Kelley, K. (2005). The Effects of Nonnormal Distributions on Confidence Intervals around the Standardized Mean Difference: Bootstrap and Parametric Confidence Intervals. Educ Psychol Meas, 65(1), 51‑69. https://doi.org/10.1177/0013164404264850
Lakens, D. (2013). Calculating and Reporting Effect Sizes to Facilitate Cumulative Science: A Practical Primer for t-Tests and ANOVAs. Front. Psychol., 4. https://doi.org/10.3389/fpsyg.2013.00863
Li, J. C.-H. (2016). Effect Size Measures in a Two-Independent-Samples Case with Nonnormal and Nonhomogeneous Data. Behav Res, 48(4), 1560‑1574. https://doi.org/10.3758/s13428-015-0667-z